
Bonjour,
Afin de pouvoir vous parler de VMware Site Recovery Manager, j’ai trouvé intéressant de faire une introduction aux différents concepts qui régissent une reprise d’activité.
Premièrement, le BCP (Business Continuity Planning) ou BCM (Business Continuity Management) est un processus de planification proactif qui assure des services ou des produits essentiels lors d’une interruption. Il doit permettre de mettre en place des procédures afin d’assurer la continuité et la survie de l’entreprise en respectant les obligations légales ou autres d’une organisation.
A tous les niveaux, seront intégrés des notions de gestion d’incidents, d’opérations et de communications, souvent oubliées, ce qui peut vite générer un déficit d’image, même si le cas a été résolus dans les meilleures conditions.
Le BCP n’englobe pas seulement l’IT, mais également la gestion des employés, avec la prise en compte de risques tel que les pandémies, les déplacements et les moyens de communications, après une catastrophe naturelle.
Il est composé du Business Continuity Plan, qui va offrir un pourcentage de disponibilité, selon la criticité de l’application, souvent lié aux SLA (Service Level Agreement).
De là, va découler des solutions de Haute Disponibilité (HA), d’un BRP (Business Resumption Plan), qui va gérer la reprise d’activité, après la perte d’un service (backup / restaure) et finalement en cas de désastre majeur du DRP (Disaster Recovery Plan).
Les solutions de DRP sont souvent confondues avec celle du Business Continuity Plan, pourtant ce ne sont pas les même procédures, métriques, et outils, bien que de plus en plus des solutions offre les deux, tel que la virtualisation de stockage (Falconstor, Datacore, Metrocluster) et le CDP (Continuous Data Protection).
La Haute disponibilité :
Pour la partie HA (High Availability), elle est mesurée à l’aide du pourcentage de disponibilité par année.
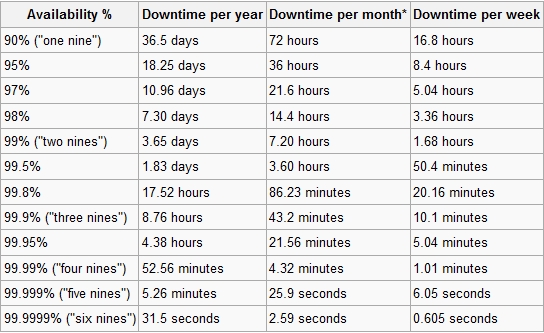
Évidemment, plus il y a de 9, derrière la virgule, plus la solution est complexe et couteuse.
C’est dans ce cas-là, que la virtualisation sort son épingle du jeu et offre d’une manière simple de la Haute Disponibilité hardware, à l’aide d’un stockage partagé et de fonctionnalité de redémarrage des VMs, perdues lors du crash de l’hyperviseur.
Autres solutions de HA, les clusters de serveurs comme le MSCS (Microsoft Cluster Service) et plus récemment le Failover Cluster pour Windows 2008 R2, qui génèrent souvent plus de problèmes qu’ils n’en résolvent…
La mode actuelle étant de mettre en place le cluster, au niveau applicatif, avec sa propre réplication, à l’image du DAG (Database Availability Group) de Microsoft Exchange 2010.
Le BRP ET DRP
Lors de la perte d’un service ou d’un datacenter, on va utiliser des métriques tel que :
Le RPO (Recovery Point Objective) perte de données définie comme étant le maximum acceptable, en cas de crise, qui va dépendre de la réplication et des backups des données.
Le RTO (Recovery time Objective) délai prédéfini dans lequel les processus critiques doivent être rétablis. Toutes vos applications et services n’auront pas forcément le même RTO, en cas de DRP. Cela pourra aller de quelques minutes à plusieurs semaines.
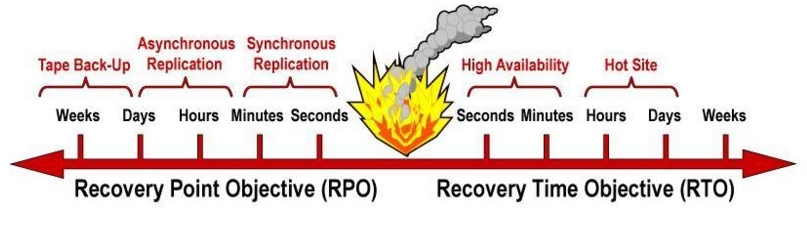
Le BRP (Business Resumption Plan) est simplement votre procédure de restauration d’un serveur, à l’aide de vos backups ou snapshots, qui vous permettrons de restaurer vos données et services.
On va utiliser ce terme lors que l’on a perdu 1 service qui n’a pas de solution de HA et donc il faudra, selon le type de crash, changer le hardware défectueux ou restaurer la donnée voire l’entier de l’OS et des données.
D’expérience, si l’on redéploye une VM et que l’on fait un full restaure, ceci pour autant qu’il n’y a pas des TB de données, il est possible de remettre en production un serveur en moins de deux heures.
Finalement le DRP, qui est une procédure lié à un crash majeur dans l’entreprise. Il existe deux types de désastre, le clinique, qui est principalement lié à l’erreur humaine et aux défauts d’infrastructures et les catastrophes naturelles.
Voici un slide du VMworld 2011 représentant les différents cas de figures.
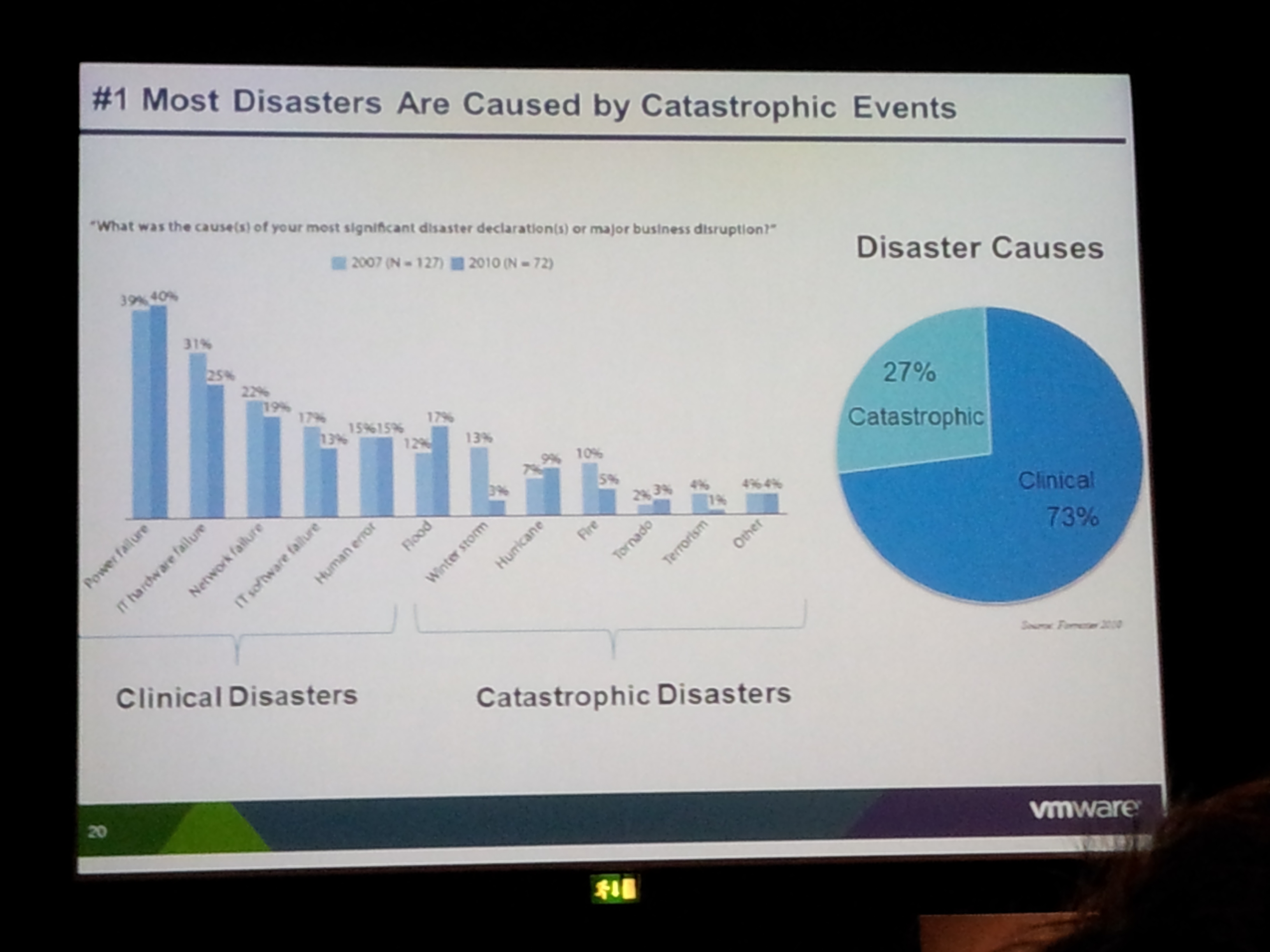
Cela va exiger un site distant, en principe à un minimum d’une soixantaine de Km de l’entreprise, afin de garantir la sécurité physique des données. C’est également dans ce type de cas que le Cloud IaaS peuvent offrir un solution simple et élastic.
VMware prévoit déjà d’intégrer SRM et vSphere Replication dans leur outil vCloud Director.
C’est lors de la perte d’un datacenter que l’on va voir si les procédures sont complètes et bien réfléchies.
En principe, si elles ont été testées, une à deux fois par année, il ne devrait pas y avoir de surprise.
Ces process devraient être fait de telles manières que n’importe quel personnel de l’IT, soit capable de remonter la production, même si c’est un sous-traitant, qui ne connait pas l’infrastructure. Sacré pari !
Une fois de plus la virtualisation permet de mettre en place de solutions de DRP simples et efficaces, à l’aide de la réplication des baies de stockage ou d’applications tiers tel que Weeam, vSphere Replication et bientôt Hyper-V Replica avec Windows 8.
C’est là que VMware SRM (Site Recovery Manager) va rentrer en jeu et permettre une reprise de production extrêmement rapide, sur le site DR.
Pour les serveurs physiques, des outils comme Double Take, Storage Fondation, Falconstor ou Datacore permettront de répliquer et représenter des LUN à des serveurs de spare, sur le site distant.
Cet article se veut une introduction et vulgarisateur, à ces différents concepts et n’est évidemment pas exhaustif, si vous avez des remarques et compléments d’informations, c’est avec plaisir que je vous laisse ajouter des compléments à cette article.
Il existe passablement de documentations et normes, qui régissent leur mise en place, notamment la norme ISO/PAS22399:2007, qui est un consensus des normes internationales.
Bon BCM
Pingback: VMware Site Recovery Manager (partie 2) |
Bonjour, merci pour cet article qui rappel les bases du Disaster Recovery Plan! Vraiment très intéressant. Contrairement à votre article, nous avons mis en place à DR plan avec la technologie SnapMirror de Netapp. Celui-ci est vraiment très simple à mettre en place, et très rapide en cas de disaster. 1 cluster Vmware et une baie Netapp sur chaque sites, et une synchronisation toutes les 30 min (RPO). En cas de problème sur le site de production, nous avons “juste” à ré-inventorier les machines virtuelles sur le site de DR et les allumer. C’est une solution simple et peu coûteuse, peu de licences, pas de logiciel tiers à connaitre… Avez vous des expériences sur ce “type” de DR plan? Merci